Mind Lab Toolkit (MinT)
为 Experiential Intelligence 构建基础设施
MinT(Mind Lab Toolkit)是一套 RL 基础设施,帮助 agent 和模型从真实经验中学习。它封装了计算调度、分布式 rollout 和训练编排,让团队可以在真实任务、真实反馈、真实产品约束下快速迭代学习循环。
MinT 提供统一且可复现的方式来运行多模型、多任务的强化学习,重点是让 LoRA RL 变得简单、稳定、高效——无论是主流模型还是前沿大模型。你只需定义训练什么、用什么数据、怎么优化、怎么评估,剩下的交给 MinT。
MinT 是什么
MinT 专注于多模型、多任务强化学习的工程和算法实现。我们特别强调让 LoRA RL(Low-Rank Adaptation Reinforcement Learning)对主流和前沿模型都做到简单、稳定、高效。
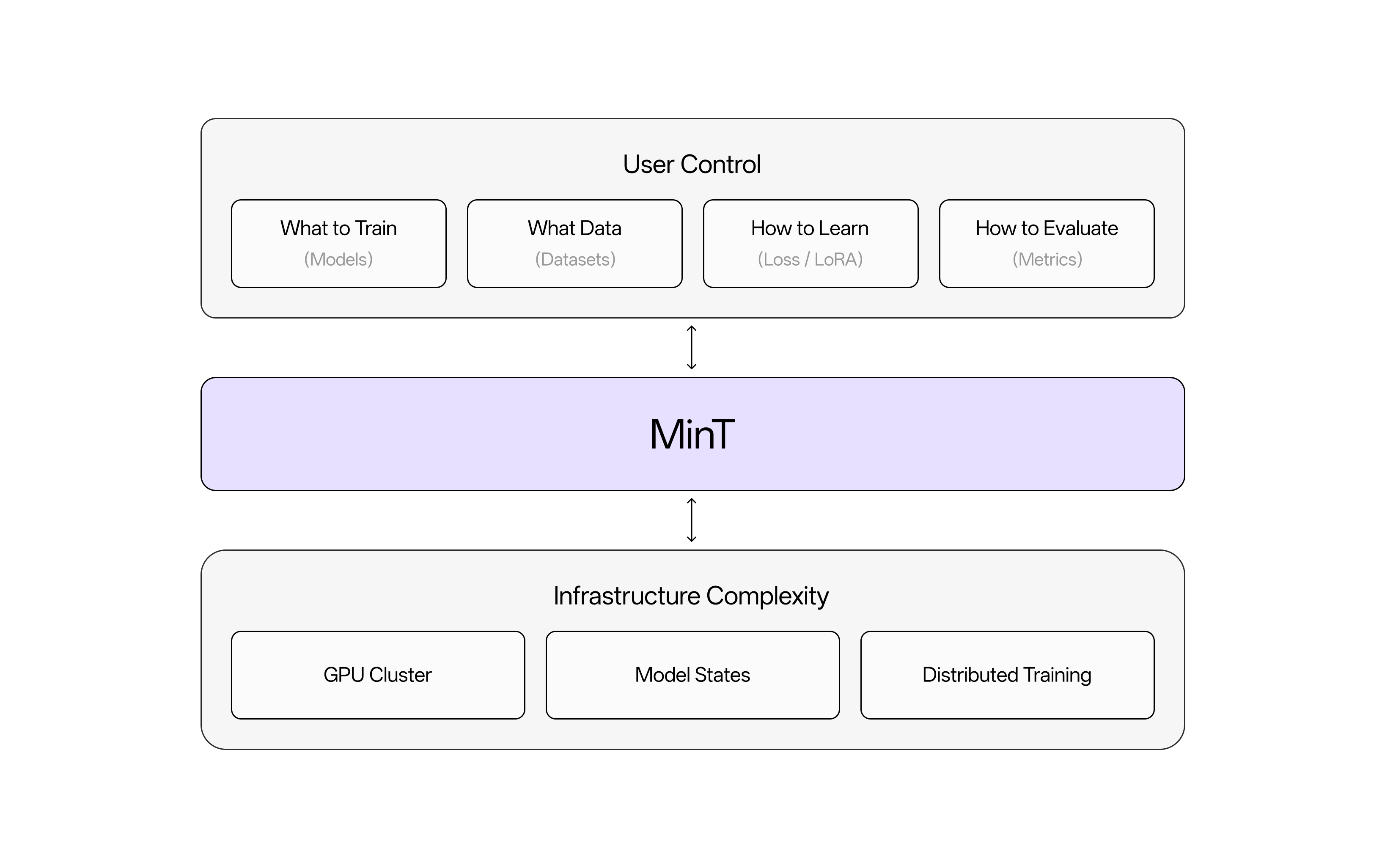
MinT 封装了基础设施的复杂性——GPU 集群、模型状态、分布式训练——让你专注于核心问题:选择模型、准备数据、定义学习目标、评估结果。
核心特性
- 模型支持:Qwen3-0.6B、Qwen3-4B-Instruct-2507、Qwen3-30B-A3B-Instruct-2507、Qwen3-235B-A22B-Instruct-2507,与服务端可用模型保持一致
- 算法支持:以 RLHF/GRPO 和通用策略优化为核心的稳健训练 pipeline
- 无缝迁移:初始 API 兼容 ThinkingMachines Tinker,作为熟悉的平替升级
- 规模化 Agentic RL:在更广泛的任务分布、更长的交互 horizon、更丰富的环境约束下采集和利用经验
当前兼容性与计划更新见 Tinker 兼容性。
核心能力
- 大模型高效训练的 LoRA fine-tuning
- 分布式数据采集和滚动训练
- 权重管理和模型发布
- 标准 CPU 集群上的在线评估
适合的用户
对于 builders:专注于理解问题和设计机制,把基础设施交给 MinT。我们开放真实业务场景中使用的工作流、评估方案和训练基础设施。
对于 researchers:通过标准化日志、可复现评估、可移植工作流和清晰的训练数据血缘,降低 RL 研究中的工程摩擦。
核心 API
forward_backward:计算并累积梯度optim_step:更新模型参数sample:从训练后的模型生成输出- 状态持久化:保存/加载 weight 与 optimizer 状态
价值观
MinT 源自 Macaron 的生产实践,已完成万亿参数级模型的端到端 LoRA(Low-Rank Adaptation)RL 训练。我们坚持以真实经验为首要约束。我们坚持工程透明。我们坚持向社区交付可复用的工作流。
联系我们
扫码添加 MinT 微信小助手,获取最新动态和技术支持: